이번 포스팅에서는
교차검증(Cross-Validation)에 대해서
학습해보겠습니다.
아래 포스팅을 보고 따라가보겠습니다.
https://wooono.tistory.com/105
[ML] 교차검증 (CV, Cross Validation) 이란?
교차 검증이란? 보통은 train set 으로 모델을 훈련, test set으로 모델을 검증한다. 여기에는 한 가지 약점이 존재한다. 고정된 test set을 통해 모델의 성능을 검증하고 수정하는 과정을 반복하면, 결
wooono.tistory.com
https://heytech.tistory.com/113
[머신러닝] 교차검증(Cross-validation) 필요성 및 장단점
📚 목차 1. 교차검증 정의 2. 교차검증의 장단점 3. 교차검증의 종류 3.1. Hold-out Cross-Validation 3.2. K-Fold Cross-Validation 3.3. Leave-p-Out Cross-Validation(LpOCV) 3.4. Leave-One-Out CV(LOOCV) 1. 교차검증 정의 교차검증
heytech.tistory.com
1. 교차검증(Cross-Validation)
transorflow 포스팅에서 한 번 다룬적이 있는
Validataion 개념의 확장입니다.
https://aigaeddo.tistory.com/20
[Tensorflow] 16. 데이터쪼개기 2) validation data
지금까지는 모델을 훈련 시킬때 훈련 데이터만 넣어 훈련시켰습니다. 해당 포스팅에서도 이 내용을 다뤘었죠! https://aigaeddo.tistory.com/10 7. 데이터) 데이터 쪼개기 (훈련 데이터, 평가 데이터) 전에
aigaeddo.tistory.com
교차검증이란 모델 훈련(Train) 데이터를
훈련용(Train), 검증용(Validation)으로 나누는데
이 것을 교차하여 번갈아 선택하여 사용해서 훈련에 사용하는 방법론입니다.

예를들어, 위 그림은 Cross Validation 방식 중 하나인 kFlod 방식이며,
k가 5인 교차검증을 나타내고 있습니다.
총 훈련 데이터셋을 5등분 해서 4:1의
훈련용 데이터셋과 검증용 데이터셋으로
나눠줍니다.
5번 반복을 통해서 5개 중 1개의 데이터셋이 꼭 한번은
검증용 데이터에 들어갈 수 있게 합니다.
이렇게 되면 모든 데이터셋을 다 이용해서
검증해 줄 수 있습니다.
2. 교차검증 방법론 종류
교차검증의 종류로서는
scikit-learn 문서만 확인해도
https://scikit-learn.org/stable/modules/classes.html#module-sklearn.model_selection
API Reference
This is the class and function reference of scikit-learn. Please refer to the full user guide for further details, as the class and function raw specifications may not be enough to give full guidel...
scikit-learn.org
Hold-out CV
K-Fold CV
Stratified K-Fold CV
Group K-Fold CV
ShuppleSplit CV
PredefinedSplit CV
Leave-p-Out CV(LpOCV)
Leave-One-Out CV(LOOCV)
Time Series Split CV
......
등 많은 방법론이 존재합니다.
저는 이 중 중복된 개념을 제외한 방법론들을
Scikit -learn으로 구현해보겠습니다!

3. Scikit -learn cross validation 사용해보기
scikit learn의 CV사용 메뉴얼을 보며 일부 방법론을 따라가볼게요!
https://scikit-learn.org/stable/modules/cross_validation.html#cross-validation
3.1. Cross-validation: evaluating estimator performance
Learning the parameters of a prediction function and testing it on the same data is a methodological mistake: a model that would just repeat the labels of the samples that it has just seen would ha...
scikit-learn.org
3-1. Hold-out CV
tensorflow에서 지금까지 해온 방식이죠.
특정 비율로서 train/test data를 1회 분할하는 방법론입니다.

scikit-learn의 model_selection 모듈의 train_test_split을 사용해서
validation data를 나눠주는 방식을 사용할 수 있습니다.
혹은 tensorflow 에서는
model 의 fit 할때 validation_split이라는 파라미터
설정으로도 가능했습니다!
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
X,y = load_iris(return_X_y=True)
print(X.shape, y.shape) #(150, 4) (150,)
#Train, test 데이터셋 분할
X_train, X_test, y_train, y_test = train_test_split(
X,y, test_size=0.4, random_state=42
)
print(X_train.shape, y_train.shape) #(90, 4) (90,)
print(X_test.shape, y_test.shape) #(60, 4) (60,)
#Train 에서 Validation 데이터셋 분할
X_train, X_val, y_train, y_val = train_test_split(
X_train, y_train, test_size=0.4, random_state=42
)
print(X_train.shape, y_train.shape) #(54, 4) (54,)
print(X_val.shape, y_val.shape) #(36, 4) (36,)
+))cross-validataion metrics 계산
scikit learn의 CV사용 메뉴얼에서는
각 CV사용 법의 설명 전에
우선 metrics의 계산법을 먼저 설명해주고 있네요.
각 cross- validation에 대한
score를 계산할 수 있습니다.
여기서 확인 할 수 있는건 SVC 모델에서는
2번째, 5번째로 나눠진
validation의 score가 좋았다고 생각할 수 있습니다.
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
clf = SVC(kernel='linear', C=1, random_state=42)
scores = cross_val_score(clf, X, y, cv=5)
print("scores : ", scores)
#scores : [0.96666667 1. 0.96666667 0.96666667 1. ]
print("acc 평균 : %0.2f" % scores.mean()) #acc 평균 : 0.98
print("acc 표준편차 : %0.2f" % scores.std()) #acc 표준편차 : 0.02
각 metrics에 대한 스코어도 확인해 볼 수 있습니다.
from sklearn import metrics
scores = cross_val_score(
clf, X, y, cv=5, scoring='f1') #f1 score
print(scores)(metrics의 종류와 scoring에 대한
자세한 설명은 아래의 문서에서 확인해보세요)
https://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter
3.3. Metrics and scoring: quantifying the quality of predictions
There are 3 different APIs for evaluating the quality of a model’s predictions: Estimator score method: Estimators have a score method providing a default evaluation criterion for the problem they ...
scikit-learn.org
**이하의 코드부분에서는 편의상 validation datasets를
test datasets 라고 통일해서 사용하겠습니다.
3-2. k-fold
위에서 예시를 들었던 방법론이죠.
k 번 접는 방법론이라고 합니다.
k 는 Fold, 몇번 접는지에 대한 횟수를 나타냅니다.
아래의 그림에서는 k 를 5로 주고
훈련용 데이터셋과 검증용 데이터셋을 4:1 로 나눠준 것을 확인할 수 있습니다.
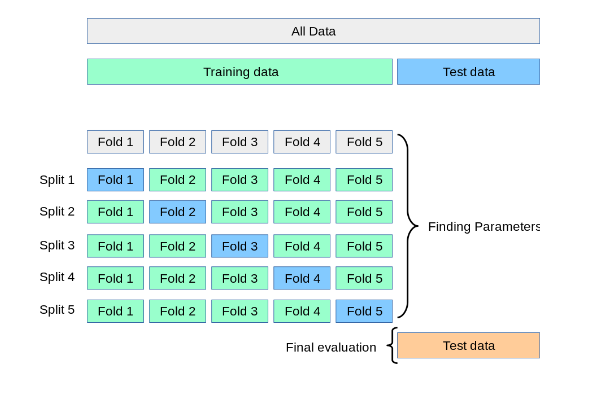
데이터는 임의로 10개를 줬지만,
위의 그림대로 k-fold의 k값을 n_splits 로서 5를 줘서
나눠준 인덱스를 확인해본 코드입니다.
그림과 동일한 방식으로 5번 나눠진 것을 확인할 수 있습니다.
import numpy as np
from sklearn.model_selection import KFold
X = np.array(['a', 'b', 'c', 'd','e','f','g','h','i','j'])
kf = KFold(n_splits=5)
for train, test in kf.split(X):
print(train, test)
'''
[2 3 4 5 6 7 8 9] [0 1]
[0 1 4 5 6 7 8 9] [2 3]
[0 1 2 3 6 7 8 9] [4 5]
[0 1 2 3 4 5 8 9] [6 7]
[0 1 2 3 4 5 6 7] [8 9]
'''
3-3. Repeated k-fold
K-fold를 몇번 반복시킬 때 사용하는 방법론이라고 하네요.
코드상 사용법은 아래와 같습니다.
RepeatedKFold를 사용하며, 반복될 값을 n_repeats파라미터로서 정해줍니다.
k-Fold의 결과보다 세분화되서 test datasets가 섞이게 되네요.
import numpy as np
from sklearn.model_selection import RepeatedKFold
X = np.array(['a', 'b', 'c', 'd','e','f','g','h','i','j'])
rkf = RepeatedKFold(n_splits=5, n_repeats=2, random_state=42)
for train, test in rkf.split(X):
print(train, test)
'''
[2 3 4 5 6 7 8 9] [0 1]
[0 1 4 5 6 7 8 9] [2 3]
[0 1 2 3 6 7 8 9] [4 5]
[0 1 2 3 4 5 8 9] [6 7]
[0 1 2 3 4 5 6 7] [8 9]
[0 2 3 4 5 6 7 9] [1 8]
[1 2 3 4 6 7 8 9] [0 5]
[0 1 3 4 5 6 8 9] [2 7]
[0 1 2 3 5 6 7 8] [4 9]
[0 1 2 4 5 7 8 9] [3 6]
[2 3 4 5 6 7 8 9] [0 1]
[0 1 2 3 4 6 7 9] [5 8]
[0 1 2 5 6 7 8 9] [3 4]
[0 1 2 3 4 5 6 8] [7 9]
[0 1 3 4 5 7 8 9] [2 6]
'''
3-4. Leave One Out(LOO)
하나를 제외하고 교차검증을 진행합니다.
즉, k-Fold 에서는 일일히 정해줬던 비율이 아닌
LOO에서는 '한개'만 무조건 테스트셋으로 만들어 주는 것 같습니다.
import numpy as np
from sklearn.model_selection import LeaveOneOut
X = np.array(['a','b','c','d'])
loo = LeaveOneOut()
for train, test in loo.split(X):
print(train, test)
'''
[1 2 3] [0]
[0 2 3] [1]
[0 1 3] [2]
[0 1 2] [3]
'''
3-5 Leave P Out (LPO)
Leave One Out 방식이 '한개'의 테스트셋으로 정해줬다면,
p를 설정해줌으로서 하나 'p개'의 테스트셋을 정해주는 방법론입니다.
import numpy as np
from sklearn.model_selection import LeavePOut
X = np.array([1,2,3,4])
lpo = LeavePOut(p=2)
for train, test in lpo.split(X):
print(train, test)
'''
[2 3] [0 1]
[1 3] [0 2]
[1 2] [0 3]
[0 3] [1 2]
[0 2] [1 3]
[0 1] [2 3]
'''
3-6 ShuffleSplit
k-Fold 방식에 Shuffle이 추가된 방식으로 보면 될 것 같습니다.
다만 아래의 그림과 같이
샘플이 먼저 섞이고 여기서 한쌍의 Train datasets와 Test datasets를
나눠서 분할한다고 합니다.

shuffle 개념이니
random_state로 난수를 설정해서 재현성이 가능하게 해줍니다.
n_splits는 나눠주는 횟수,
test_size 나 train_size는 개수가 아닌 비율로 선택합니다.
import numpy as np
from sklearn.model_selection import ShuffleSplit
X = np.arange(10)
ss = ShuffleSplit(n_splits=5, test_size=0.4, random_state=42)
for train_index, test_index in ss.split(X):
print("%s %s" % (train_index, test_index))
'''
[7 2 9 4 3 6] [8 1 5 0]
[3 4 7 9 6 2] [0 1 8 5]
[8 5 3 7 1 4] [9 2 0 6]
[8 0 3 4 5 9] [1 7 6 2]
[0 7 6 3 2 9] [1 5 4 8]
'''
3-7 Stratified k-fold
train_test_split 에서 stratify 라는 파라미터가 기억나시나요?
분류를 해줄때, train 과 test datasets의 y값 클래스(Lable) 비율이 골고루
섞이게끔 해주는 파라미터죠.
동일한 개념이 k-fold에 추가되었다고 생각하시면 됩니다.
import numpy as np
from sklearn.model_selection import StratifiedKFold, KFold
X, y = np.ones((50,1)), np.hstack(([0] * 45, [1] * 5)) #label의 개수 0 : 45개 1: 5개
skf = StratifiedKFold(n_splits=3)
print("StrartifiedKFold")
for train, test in skf.split(X, y):
print(f'train : {np.bincount(y[train])} | test : {np.bincount(y[test])}')
print("="*30)
print("kFold")
kf = KFold(n_splits=3)
for train, test in kf.split(X, y):
print(f'train : {np.bincount(y[train])} | test : {np.bincount(y[test])}')
'''
StrartifiedKFold
train : [30 3] | test : [15 2]
train : [30 3] | test : [15 2]
train : [30 4] | test : [15 1]
==============================
kFold
train : [28 5] | test : [17]
train : [28 5] | test : [17]
train : [34] | test : [11 5]
'''클래스의 비율이 골고루 분배된 것을 확인할 수 있습니다.
3-8 Group k-fold
그룹을 골고루 나눠주는 k-fold 방식이라고 합니다.
예를들어 각 학급의 학생들의 데이터가 있다면
학급마다의 데이터가 그룹이 되고
이 그룹의 비율을 균형있게 나눠준다고 합니다.
그렇기 때문에 n_splits는 그룹의 종류 개수를 넘어갈 수 없습니다.
import numpy as np
from sklearn.model_selection import GroupKFold
X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 8.8, 9, 10]
y = ["a", "b", "b", "b", "c", "c", "c", "d", "d", "d"]
groups = [1, 1, 1, 2, 2, 2, 3, 3, 3, 3]
gf = GroupKFold(n_splits=3)
for train, test in gf.split(X,y,groups= groups):
print(train, test)
'''
[0 1 2 3 4 5] [6 7 8 9]
[0 1 2 6 7 8 9] [3 4 5]
[3 4 5 6 7 8 9] [0 1 2]
'''
3-9 Time Series Split
시계열 데이터의 데이터 교차 검증 분할방식입니다.
때문에 이전 교차검증이랑은 개념이 많이 다른듯 하네요.
timesteps을 늘려가며 입력데이터를 분할해주는 것 같습니다.
시계열데이터의 경우 랜덤성이 부여되면 안되며,
시간축에 따라 과거데이터부터 train, test datasets를 나눠준다고 합니다.

ahead gap 간격을 고려해서 나눠줄 수도 있습니다.

이미지 출처 : https://sosoeasy.tistory.com/373
import numpy as np
from sklearn.model_selection import TimeSeriesSplit
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4, 5, 6])
tscv = TimeSeriesSplit(n_splits=3)
print(tscv) #TimeSeriesSplit(gap=0, max_train_size=None, n_splits=3, test_size=None)
TimeSeriesSplit(gap=0, max_train_size=None, n_splits=3, test_size=None)
for train, test in tscv.split(X):
print(train, test)
'''
[0 1 2] [3]
[0 1 2 3] [4]
[0 1 2 3 4] [5]
'''
#gap = 1
TimeSeriesSplit(gap=1, max_train_size=None, n_splits=3, test_size=None)
for train, test in tscv.split(X):
print(train, test)
'''
[0 1 2] [3]
[0 1 2 3] [4]
[0 1 2 3 4] [5]
'''
교차검증의 장점은 무엇보다
데이터를 효율적으로 사용해서 모델을 훈련시킬 수 있는 것이겠네요
단점은 반복적인 과정이므로
시간이 더 걸리게 됩니다.
데이터양에 따라서 잘 생각해서 교차검증을 사용한다면
효율적인 모델 훈련을 진행할 수 있을 것 같습니다!
잘못된 부분 있으면 지적 남겨주시면 감사하겠습니다!
'인공지능 개발하기 > Machine Learning' 카테고리의 다른 글
| 결정트리(Decision Tree) (0) | 2024.03.28 |
|---|---|
| 하이퍼파라미터 최적화 (Hyperparameter Optimization) (1) | 2024.02.18 |
| 퍼셉트론과 XOR 문제 (0) | 2024.02.18 |
| SVM(Support Vector Mchine) (1) | 2024.02.13 |
| [Tensorflow] 32. 앙상블(Ensemble) (1) | 2024.02.11 |



