감사하게도 Google ML Bootcamp를 통해
여러 테크톡을 들을 수 있었고,
이 중 AI/ML GDE 이준범(Beomi)님의 "Gemma-Ko:오픈 언어모델에 한국어 입히기"
테크톡 내용을 정리해보려고 합니다.
1. Gemma 란?
Google에서 공개한 Opensource LM입니다.
Google의 또 다른 모델인 Gemini와 비교해보자면
Gemini: Google의 LLM/LMM(large multimodal model).
Gemma: 구글의 공개 LM(Open source).
라고 볼 수 있습니다.
Gemini와 Gemma는 토크나이저가 동일하다고 합니다.
다국어로 훈련된 Gemini와 다르게 Gemma 모델은 영어로만 학습된 모델입니다.
다만 토크나이저에는 한국어 Vector 정보가 있어
Gemma는 한국어를 할 수 있지만 잘 하지 못합니다.
Gemma-1은 2024년 2월 공개되었으며, Gemma-1_2B 모델과 7B 모델로 출시되었습니다.
출시 당시에 LLama2 7B, LLama2 13B Mistral 7B 모델과 Gemma 7B를 비교했고
더 작고 성능이 높은 모델로 벤치마크하였습니다.
이후 긴 시퀀스 입출력이 가능한 Reccurent Gemma 모델(2024.04)과
Image 입력이 가능한 PaliGemma(2024.05) 모델을 출시하였고,
LLama3 등장 이 후 2024년 6월 Gemma2 모델을 출시합니다.
2. Gemma 2
2- 1. Interleaved Attention
Gemma1의 입출력은 8k sequence까지 가능합니다.
Gemma2에서는 더 긴 sequence 입출력을 위한 슬라이딩 윈도우 Attention 방식을 적용했습니다.
이 방식을 Interleaved Attention이라고 합니다.
레이어 마다 local attention, global attention 을 진행해서 사용량은 줄이고, sequence length를 늘릴 수 있었습니다.
2-2. GQA
또한, Multi-head Attention 대신 계산량을 줄이고자
Multi-query Attention(MQA)가 고안되었습니다.
MQA는 하나의 Key, Value만을 공유합니다. 즉 Key와 Value는 같은 가중치를 갖게 됩니다.
때문에 MQA는 다양한 패턴을 학습하는데 제한이 있을 수 있고 이로 인해, 성능이 떨어지게 되므로
Grouped-query Attention(GQA)이 고안되었습니다.
Key와 Value를 완전 공유하는 대신 여러 그룹으로 묶어 Key와 Value를 공유합니다.
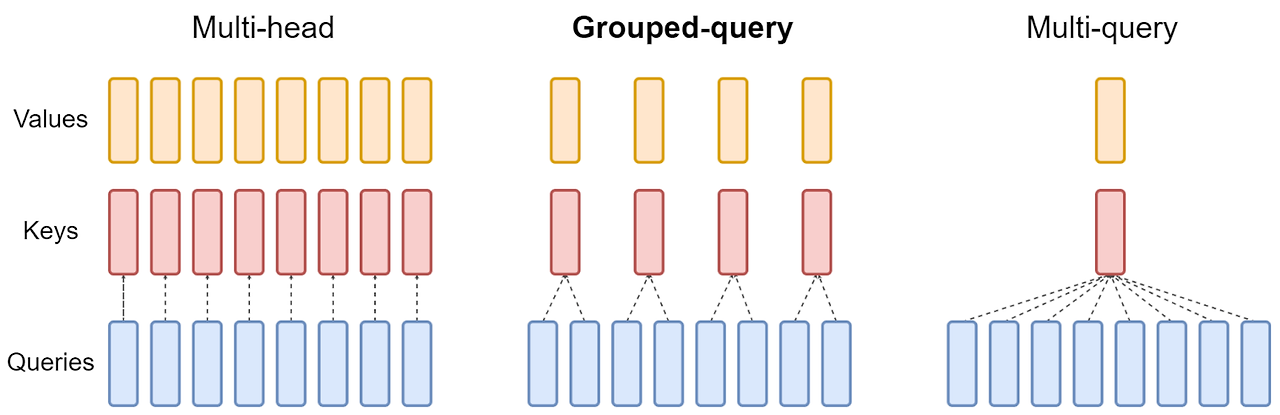
Gemma2에서는 해당 GQA 방식을 채택합니다.(LLama2에서도 적용된 방식)
2-3. Online Knowledge Distillation
Gemma2모델은 27B, 8B, 2B 모델을 내놓았습니다.
이 중 27B 모델은 13T tokens를 생바닥부터 학습을 진행합니다.
9B, 2B 모델은 가장 크고 성능이 좋은 27B 모델을 가지고 knowledge Distillation 학습을 진행합니다.
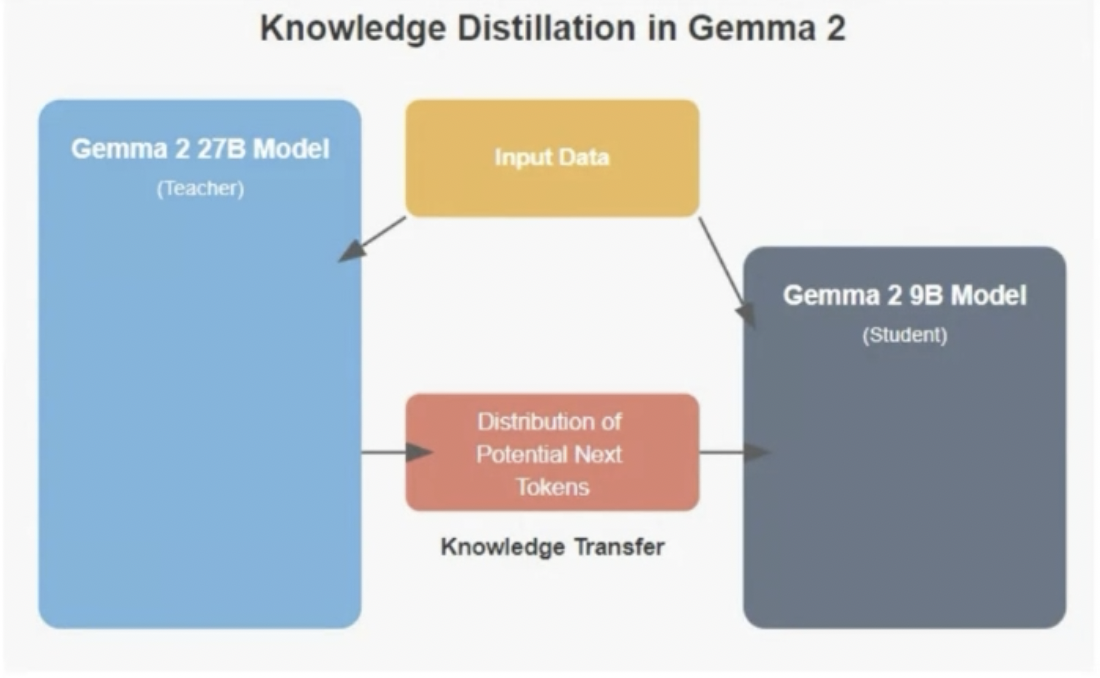
27B 모델의 결과를 따라하도록 학습하며, 노이즈 같은 분포의 상대적 영향은 덜받으며
성능을 향상시킬 수 있다고 합니다.
이런 학습을 위해서는 각 모델은 동일한 Tokenizer를 가져야 합니다.
3. Gemma-Ko 프로젝트
Gemma는 영어로 훈련된 모델이며, 한국어를 잘 하지 못하기 때문에
연사자님은 한국어를 잘하는 Gemma 모델을 생성하는 Gemma-Ko 프로젝트를 진행했습니다.
*여기서 한국어를 잘한다는 의미는 무엇일까?
- 한국어 문법을 잘 지킨다.
- 한국인스럽게 말한다.
- 한국 문화를 잘 안다.
- 한국어로 다양한 지식 답변을 잘 한다.
- 등등.....
이라고 생각을 정리해주셨습니다.
Fine-Tuning, Pre-training의 개념도 짚고 넘어가 주셨습니다.
Fine-Tuning : 내가 원하는 질문 답변, 채팅데이터 등으로 학습을 진행하여 내가 원하는 스타일로 답변하게 만듦.
Pre-Traing: Fine-Tuning 전단계. 도메인에 대한 지식을 입히는 단계.
시도 방식은 2가지로 진행을 생각하셨다고 합니다.
1. "한국을 보다 잘 아는 언어모델" 만들기
2. "한국어로 자연스럽게 말하게" 만들기
Gemma-Ko프로젝트는 1번을 채택해서 진행되었으며,
2번 연구도 계속 진행하고 계시다고 합니다.
Gemma -Ko 학습은 JAX/Flax를 이용해서 진행하였으며
AI-Hub, 모두의 말뭉치 데이터와
커뮤니티, 블로그, 카페 글, 쇼핑몰 리뷰, 네이터 댓글, 뉴스 댓글 등 500G 내외의 데이터를
가지고 학습을 진행했다고 합니다.
데이터 전처리는 Eleuther AI/ DPS 라는 라이브러리를 사용하였습니다.
또한, 한국어, 영어, 중국어, 일본어의 다국어 데이터로 훈련한 Gemma-mling(multilingual) 모델도 생성했는데,
Gemma-Ko 모델보다 한국어 구현 성능이 더 좋았다고 합니다.
4. 유사 프로젝트 진행 시 Tip
프로젝트 진행에 대한 Tip을 주셨습니다.
1) 현실적인 컴퓨터 리소스 : Google colab, Kaggle notebooks, Runpod 이용. A100 40G~80G 수준에서 학습이 가능할 것.
2) Fine-tunning 라이브러리: LoRa, OLoRa
3) VRAM 메모리를 좀 더 효율적으로 사용하고 싶다 => LOMO Optimizer 라이브러리 사용 / 사용 방법 예
4) 과정은 아래로 진행해보기
(결국 step by step으로 진행하며 서비스가 가능한 가장 효율적인 모델을 만들기.)

5. 느낀점
저는 이번 테크톡을 듣고,
연사자님의 LLM의 서비스의 프로젝트 진행 시 고려하셨던 생각들이 인상이 남았습니다.
다시 한번 프로젝트를 진행할 때 목적을 정확히 아는것이 중요하다고 생각이 듭니다.
Gemma에 대한 이해는 물론이고,
단순히 "한국어를 잘하는 모델 = 한글을 입출력 값으로 갖는 모델"이라고 생각하고 있었는데
"한국어를 잘하는 것이 무엇일까?" 을 생각하는 힘.
시도 방식을 최종 목표까지 여러개 생각해놓고
Step by Step로 시도해 가며 가장 효율적인 모델로 서비스하는 것을 최종 목표로 찾아 나가는 과정.
즐겁게 설명하는 강연 태도 등등....
배울 점이 많았던 테크톡이었습니다.
'인공지능 개발하기 > Bootcamp & Conference 참여' 카테고리의 다른 글
| [Conference] 모두의연구소 MODUCON 2024 후기 (0) | 2024.12.29 |
|---|---|
| [Coursera] 1. Neural Networks and Deep Learning - Week 2. Neural Networks Basics(1) (0) | 2024.09.10 |
| [Coursera] 1. Neural Networks and Deep Learning - Week 1. Introduction to Deep Learning (0) | 2024.09.09 |
| [Conference]Google I/O Extended 2024 Incheon 회고 (0) | 2024.07.29 |
| [MLB2024]Google ML Bootcamp 5기 도전 (2) | 2024.06.26 |



