이번 포스팅에선
학원에서 배운 내용이지만
완전마스터하기 위해서
CNN (Convolutional neural network) 이 뭔지
더 찾아보고 학습하겠씁니다.
저는 해당 두 블로그가 정리를 정말 잘해주셔서
참고하며 학습해보겠습니다!
(두 블로그는 꼭 한번 봐주세여...이해쏙쏙입니다.)
[딥러닝 모델] CNN (Convolutional Neural Network) 설명
저번 포스팅에서는 딥러닝의 모델별 특징에 대해 알아보았습니다. 2021.07.10 - [SW programming/Computer Vision] - AI, 머신러닝, 딥러닝 이란? 그리고 딥러닝 모델 종류 그리고 이번 포스팅에서는 그 중 Compu
rubber-tree.tistory.com
[딥러닝/머신러닝] CNN(Convolutional Neural Networks) 쉽게 이해하기
필자는 뉴욕에서 머신러닝 전공으로 석사학위 취득과정에 있습니다. 학교 수업을 듣고 실습 과제를 하며 항상 느끼는 점은 이 분야는 무엇보다도 튼튼한 이론지식이 중요하다는 것입니다. 물론
mijeongban.medium.com
1. CNN(Convolutional neural network)이란??
이미지의 특징, 패턴을 찾고 분류를 할 수 있게 해주는 유용한
합성곱 신경망입니다.
이미지 데이터는 기본적으로 4차원 형태
(예를 들어, 1024x1024, 컬러정보, 이미지 개수)인데,
딥러닝 훈련을 위한 DNN(Deep Neural network)의 값으로
넣어주기 위해서는 1차원으로 만들어줘야 합니다.
하지만 1차원의 이미지 데이터로 변경되면
이미지 고유의 공간적인 정보가 손실되고
학습 효율성이 저하된다고 합니다.
그래서 이미지의 차원 형태는 최대한 유지하면서
효율적으로 학습할 수 있도록 고안된 방식이
CNN이라고 하네요!
(얀 르쿤 좌.... 그저 빛..)
2. 구조
이해하기 쉽게 그림부터 살펴봤습니다.

위 그림의 CNN 모델의 구조를 살펴보면
feature extraction / classification 단으로 나뉘네요.
feature extraction 단의 레이어에서는 이미지들의 특징을 추출합니다.
그리고 추출한 이미지 특징 데이터를 1차원으로 평평하게 만든 후
clssification 단의
Fully connected Layer로 넣어서 가중치를 연산하는 구조네요.
3. Convolution(합성곱) 방식
일단 합성곱 방식을 설명하기 전에
해당 그림으로 용어를 정리해 보겠습니다.

height: 이미지의 높이(픽셀의 세로 개수)
width: 이미지의 너비(픽셀의 가로 개수)
channel: 이미지의 색상 데이터 개수 (흑백이면 1, RGB면 3)
이미지 데이터는 이미지의 개수, height. width, channels 의
4차원 텐서(tensor)데이터입니다.

빨간색 네모를 Kernel 이라고 하는데요,
kernel로 이미지 부분 부분을 훑으면서
특징을 찾아냅니다.
그럼 Kernel이 뭐고 어떻게 훑으면서
특징을 찾아낼까요?

좌측은 이미지, 우측은 Kernel입니다.
(Filter도 동일한 단어군요. )

이런식으로 3x3 커널로 4x4이미지를 훑는다고 하면
좌측 상단부터 우측하단까지 각각의 칸의 곱을하고 그 값들을 더해서
Convolution의 결과로 써줍니다.
예를들어 첫번째 그림을 합성곱해보자면
0*1 + 1*0 +7*1 + 5*1 + 5*2 + 6*0 + 5*3 + 3*0 + 3*1 = 40
이 되게 되는거죠.
이 합성곱의 원리는 행렬의 Inner product(내적)이라는
연산처리 방식이라고 합니다.
(A와 B의 합성곱: a1*b1 + a2*b2 + a3*b3 + a4*b4)

그리고 Convolution의 결과의 형태는
(이미지의 height - 커널의 height + 1 , 이미지의 width - 커널의 width + 1) 의
크기를 가진다고 합니다.
예를들어,
이미지 : 4x4 , 커널 : 2x2 가 있다고하면
결과의 형태는 (4-2 + 1 , 4-2 + 1).
즉 3x3의 형태가 됩니다.
이 그림을 다시 보면 4x4이미지와 3x3 kernel의 합성곱의 결과는
2x2(4-3+1, 4-3+1) 가 되었죠?
4. Stride
위에서 커널로 이미지를 1칸씩 이동하면서 합성곱을 구했죠?
이 1칸씩 이동을 Stride라고 합니다.
(Stride = 보폭)
일반적으로 Stride는 1이며,
2칸씩,3칸씩....n칸씩이동도 가능합니다.
다만 stride가 커질수록
연산을 빨라지겠지만 데이터의 손실이 커지게 됩니다.

5. Padding
위에서 4x4 이미지, 2x2 커널이 있다고하면
Convolution의 결과의 형태는 3x3의 형태가 된다고 했었죠?
Convolution을 거치며 크기가 작아졌고
이는 데이터 손실이 발생한 거라고 하네요.
그래서 이 줄어든 부분을 채우는 방식이 padding이라고 합니다.
주로 빈 부분을 0으로 채우는 zero-pedding이 사용된다고 합니다.

6.Pooling
위의 CNN 구조 그림에서도 나와있는데,
CNN 구조에서 feature extraction Pooling Layer를 볼 수 있었습니다.
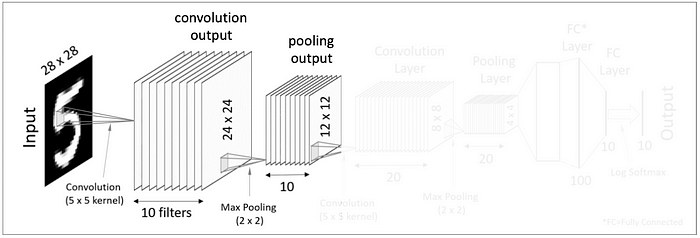
이 Pooling Layer 의 Pooling은 뭘까요?
feature extraction 단의 이미지의 크기를 유지한채
데이터가 classification 단의 Fully connected Layer에 들어가면
연산의 크기가 기하급수적으로 늘어난다고 합니다.
이런 이유로 이미지의 크기도 줄이고
특정 feature를 강조하는 방식이 Pooling이라고 합니다.
Pooling에는
Max Pooling, Average Pooling, Min Pooling 3가지 방식이 있다고합니다.
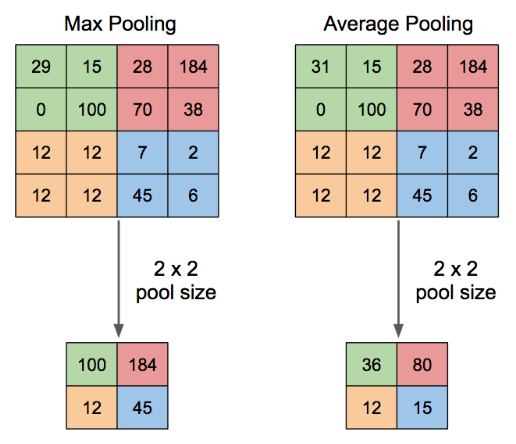
위 그림처럼 4x4 이미지가 있다면
2x2 사이즈의 Max Pooling Layer 를 거치게 되면
2x2마다의 최대값을 결과로 가집니다.
(Average, Min Pooling Layer도 동일한
방식을 가집니다.)
Pooling을 거친 모양은
이미지 크기/ pool size 가 됩니다.
4x4 이미지가 2x2의 Pooling을 거치면
2x2가 되는거죠.
위의 Convolution의 결과의 이미지 크기 계산과
Pooling 이미지 크기의 계산을 잘 알수 있어야
이미지가 소멸되지 않고
적절한 형태의 결과로 나오도록
모델링을 할 수 있다고 합니다.
다음 포스팅에서 직접 코드에 적용해서
CNN 모델의 "Hello World"
mnist 데이터 분류를 다뤄보겠습니다.
틀린점이 있다면 지적주세요!
'인공지능 개발하기 > Machine Learning' 카테고리의 다른 글
| [Tensorflow] 27. ImageDataGenerator 이미지 데이터 전처리(preprocessing) (0) | 2024.01.27 |
|---|---|
| [Tensorflow] 26. CNN 이미지 분류하기 (mnist) (0) | 2024.01.22 |
| [Tensorflow] 24. tensorflow GPU 가상환경 설정하기 (0) | 2024.01.20 |
| [Tensorflow] 23. 모델(Model) 구조와 가중치(Weights) 저장하기, 불러오기 (0) | 2024.01.20 |
| [Tensorflow] 22. 데이터 스케일링(Data Scaling) (0) | 2024.01.20 |



